「マシンリーダブル」を意識する
「マシンリーダブル (machine-readable)」という言葉をご存知でしょうか?
「マシン (=人間ではない、テクノロジーによって作られたシステムやツール) が、情報を認識したり解釈したりできる」ことを意味する言葉ですが、Web サイトを構築したり、Web コンテンツを発信したりするうえで、極めて重要で不可欠な概念です。
Web を利用するのは「人間」なのに、なぜ「マシンリーダブル」という概念が重要なの?...と訝しがられるかもしれませんが、実際に人間 (ユーザー) がどう Web を活用するのか、を考えると、この概念の重要性を理解できると思います。
あらゆる Web コンテンツはユーザーエージェントを介してユーザーに届く
Web の場合、「マシンリーダブル」の「マシン」は便宜的に「ユーザーエージェント」と言い換えることができるかと思いますが、Web 上のあらゆる情報 (すなわちコンテンツ) は、このユーザーエージェントを介してのみ、ユーザーに届けることができます。
ユーザーエージェントを具体的に挙げると、以下のように色々ありますが :
- ユーザーエージェントの例 (ハードウェア)
- PC、タブレット、スマートフォン、などの閲覧端末
- ユーザーエージェントの例 (ソフトウェア)
- ブラウザ、RSS リーダー、ソーシャルメディアのアプリ、スクリーンリーダーをはじめとする支援技術、検索エンジン (クローラー)、など
これらのハードウェアやソフトウェアを使うことで初めて、ユーザーはコンテンツを利用することができる、ということは、容易に想像できると思います。
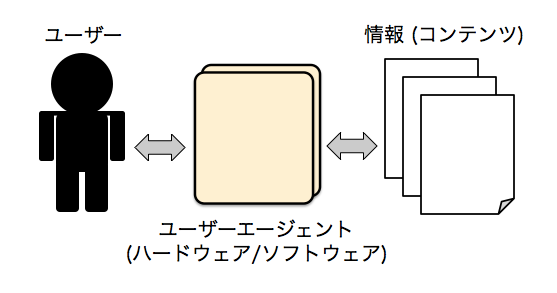
つまり Web コンテンツは、ユーザーによってアクセスされる以前に、まずはマシン (ユーザーエージェント) が取り扱える形式になっている必要があります。そしてマシン (ユーザーエージェント) は人間と違って融通の利く解釈/理解をすることができないので、マシン (ユーザーエージェント) が解釈/理解できる形に、あらかじめ情報を成型してあげる必要があるのです。
これが、Web において「マシンリーダブル」が極めて重要であることの所以です。
コンテンツをセマンティックにすることが求められる
「マシンリーダブル」であるためには、つまりユーザーエージェントが情報を適切に認識したり解釈したりできるようにするためには、コンテンツが意味的に適切に構造化されていること (セマンティックであること) が求められます。Web サイトを制作したり運用したりするうえでは、具体的な方策として、以下のようなことに留意する必要があります。
- Web 標準に則って正しくコーディングし、情報の論理構造 (見出し、段落、強調箇所、リンク、箇条書き、挿絵、など) を明確にする。
- HTML の仕様で定義されている各要素 (いわゆる「タグ」) は、本来の目的のために使う (たとえば、<table> 要素はあくまでもデータテーブルを表現するために使用し、ページレイアウトを整える目的で透明な <table> を使用しない)。
- 基本的に情報はテキスト化 (文字情報化) する。マシンがそのままでは解釈/理解できない情報 (画像、動画、音声など) は、代替となるテキスト情報を用意する。
- 適切なタイトル情報やメタ情報を盛り込み、コンテンツのアイデンティティを明確化する。
- 見栄え (ビジュアルデザイン) を整えるためのコーディングは、別途スタイルシートで行なう。
こういったことを徹底することで、アクセシビリティや SEO (検索エンジン最適化) といった面で効果があるほか、ソーシャルメディアや RSS フィードなど、自サイトの外側 (Web エコシステム) で生じる様々な情報活用シーンにおいても、利便性の向上が期待できます。また、将来、当たり前になると思われる「セマンティックウェブ (semantic web)」にもスムーズにつながってゆくことができそうです。
ユーザビリティを近視眼的に考えてしまうと、つい、人間が認識/解釈できる範囲 (目に見えるユーザーインターフェースや情報デザイン) に意識が行きがちになりますが、こと Web においては、その裏側にあるテクノロジカルな部分 (マシンリーダブルであること) も同等に意識することで、結果、より多くのユーザーに、より豊かなユーザーエクスペリエンスを提供できると思います。その意味で、Web に携わるすべての人に「マシンリーダブル」を意識していただけたら...と思います。